Setup
The smoothLRC method uses a smoothing parameter (\(\lambda\)) and a rank parameter (\(k\)) to produce results. This article demonstrates the selection of these parameters.
Load Data
Using the spatialLIBD package, we’ll load sample 151671 from the DLPFC data.
sample <- "151671"
sce <- spatialLIBD::fetch_data(type = "sce")
sce <- sce[, sce$sample_name == sample]Parameter Grid
Here we’ll consider \(\lambda=(5, 10, 15)\) and \(k=(10, 20)\). Further, we’ll use 100 pixels as a test size.
lambdas <- c(5, 10, 15)
ks <- c(10, 20)
parameter_grid <- expand.grid(lambda = lambdas, k = ks)
test_size <- 100Cross-Validation
Next, we’ll use cross-validation to select the optimal parameter values.
metrics <- NULL
for(combo in 1:nrow(parameter_grid)){
print(parameter_grid[combo,])
combination <- smooth_cv(sce, lambda = parameter_grid[combo,"lambda"], k = parameter_grid[combo,"k"], test_size, maxiter = 5)
metrics <- rbind(metrics, tibble(lambda = parameter_grid[combo,"lambda"],
k = parameter_grid[combo,"k"],
penal_lik = combination$penal_like,
cv_like = combination$cv_like)
)
}
#> lambda k
#> 1 5 10
#> [1] "Initializing components..."
#> [1] "Running smoothLRC on training set..."
#> iteration: 1 | convergence: 0.422554 | 0.0563444 | 1
#> iteration: 2 | convergence: 0.173078 | 0.0404936 | 0.00987567
#> iteration: 3 | convergence: 0.163679 | 0.0450668 | 0.0102672
#> iteration: 4 | convergence: 0.175742 | 0.0471282 | 0.0110242
#> iteration: 5 | convergence: 0.182077 | 0.0482414 | 0.0120774
#> [1] "Compute neighborhood likelihood..."
#> [1] "Done!"
#> lambda k
#> 2 10 10
#> [1] "Initializing components..."
#> [1] "Running smoothLRC on training set..."
#> iteration: 1 | convergence: 0.422057 | 0.0554037 | 1
#> iteration: 2 | convergence: 0.164508 | 0.0401319 | 0.00985858
#> iteration: 3 | convergence: 0.161535 | 0.0453195 | 0.010362
#> iteration: 4 | convergence: 0.186979 | 0.0486879 | 0.0112138
#> iteration: 5 | convergence: 0.184922 | 0.0508453 | 0.012346
#> [1] "Compute neighborhood likelihood..."
#> [1] "Done!"
#> lambda k
#> 3 15 10
#> [1] "Initializing components..."
#> [1] "Running smoothLRC on training set..."
#> iteration: 1 | convergence: 0.42013 | 0.0539799 | 1
#> iteration: 2 | convergence: 0.167513 | 0.0398524 | 0.00986839
#> iteration: 3 | convergence: 0.176619 | 0.0454105 | 0.0104753
#> iteration: 4 | convergence: 0.191349 | 0.0489113 | 0.0113943
#> iteration: 5 | convergence: 0.181778 | 0.0511128 | 0.012534
#> [1] "Compute neighborhood likelihood..."
#> [1] "Done!"
#> lambda k
#> 4 5 20
#> [1] "Initializing components..."
#> [1] "Running smoothLRC on training set..."
#> iteration: 1 | convergence: 0.496827 | 0.0727383 | 1
#> iteration: 2 | convergence: 0.234482 | 0.0531852 | 0.0114419
#> iteration: 3 | convergence: 0.209897 | 0.0595182 | 0.0125506
#> iteration: 4 | convergence: 0.185418 | 0.0596158 | 0.0143264
#> iteration: 5 | convergence: 0.183947 | 0.0612591 | 0.0167131
#> [1] "Compute neighborhood likelihood..."
#> [1] "Done!"
#> lambda k
#> 5 10 20
#> [1] "Initializing components..."
#> [1] "Running smoothLRC on training set..."
#> iteration: 1 | convergence: 0.492975 | 0.0694401 | 1
#> iteration: 2 | convergence: 0.227639 | 0.0526918 | 0.0111891
#> iteration: 3 | convergence: 0.2107 | 0.0592167 | 0.012326
#> iteration: 4 | convergence: 0.191362 | 0.0600496 | 0.0141495
#> iteration: 5 | convergence: 0.191143 | 0.0630135 | 0.0165308
#> [1] "Compute neighborhood likelihood..."
#> [1] "Done!"
#> lambda k
#> 6 15 20
#> [1] "Initializing components..."
#> [1] "Running smoothLRC on training set..."
#> iteration: 1 | convergence: 0.491289 | 0.0671663 | 1
#> iteration: 2 | convergence: 0.238924 | 0.052163 | 0.0110855
#> iteration: 3 | convergence: 0.201901 | 0.0582762 | 0.0122061
#> iteration: 4 | convergence: 0.189654 | 0.0588165 | 0.0140169
#> iteration: 5 | convergence: 0.187515 | 0.0622647 | 0.0163196
#> [1] "Compute neighborhood likelihood..."
#> [1] "Done!"
metrics %>%
ggplot(aes(x = lambda, y = cv_like)) +
geom_point() +
geom_line() +
facet_wrap(~k) +
ylab("CV Likelihood")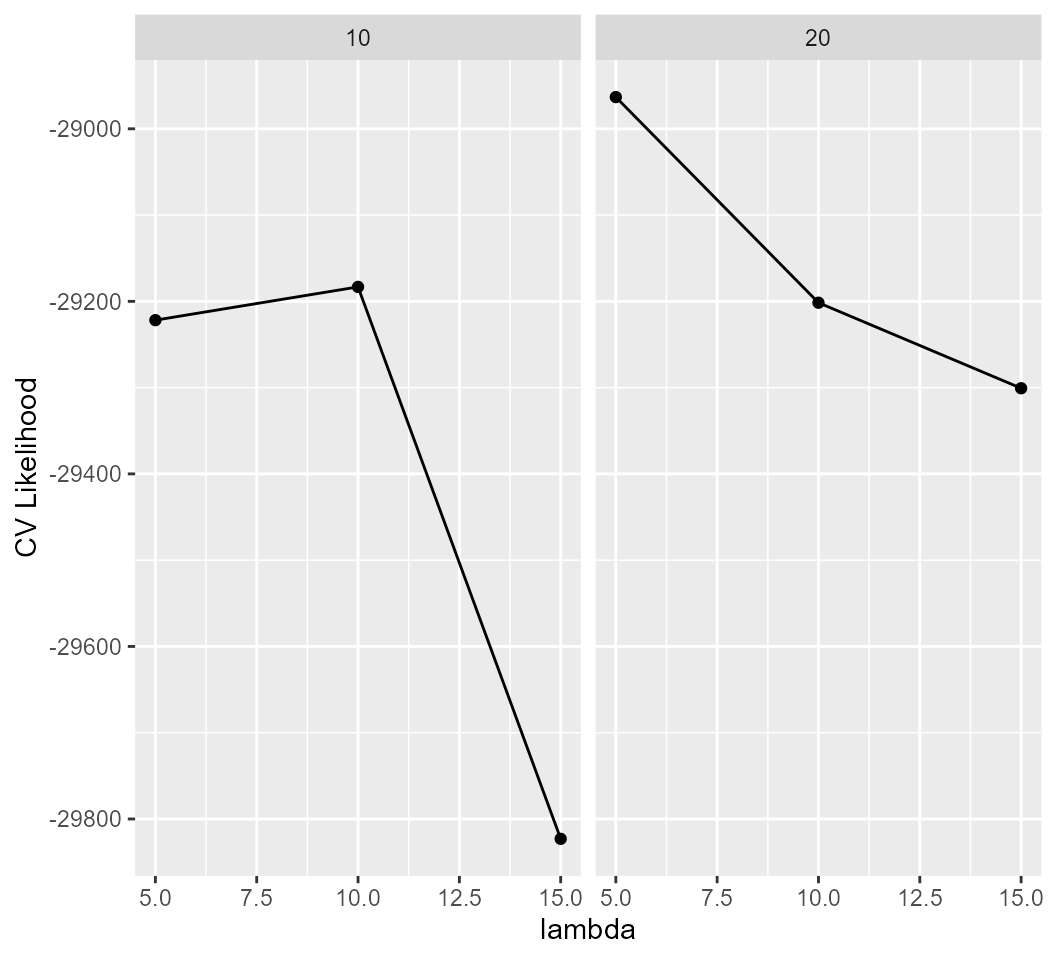
metrics %>%
group_by(k) %>%
slice_max(order_by = cv_like, n = 1) %>%
ungroup() %>%
mutate(Selected = ifelse(penal_lik == max(penal_lik), "Yes", "No")) %>%
ggplot(aes(x = k, y = penal_lik, label = lambda)) +
geom_point() +
geom_line() +
geom_label(aes(color = Selected)) +
ylab("Penalized Likelihood")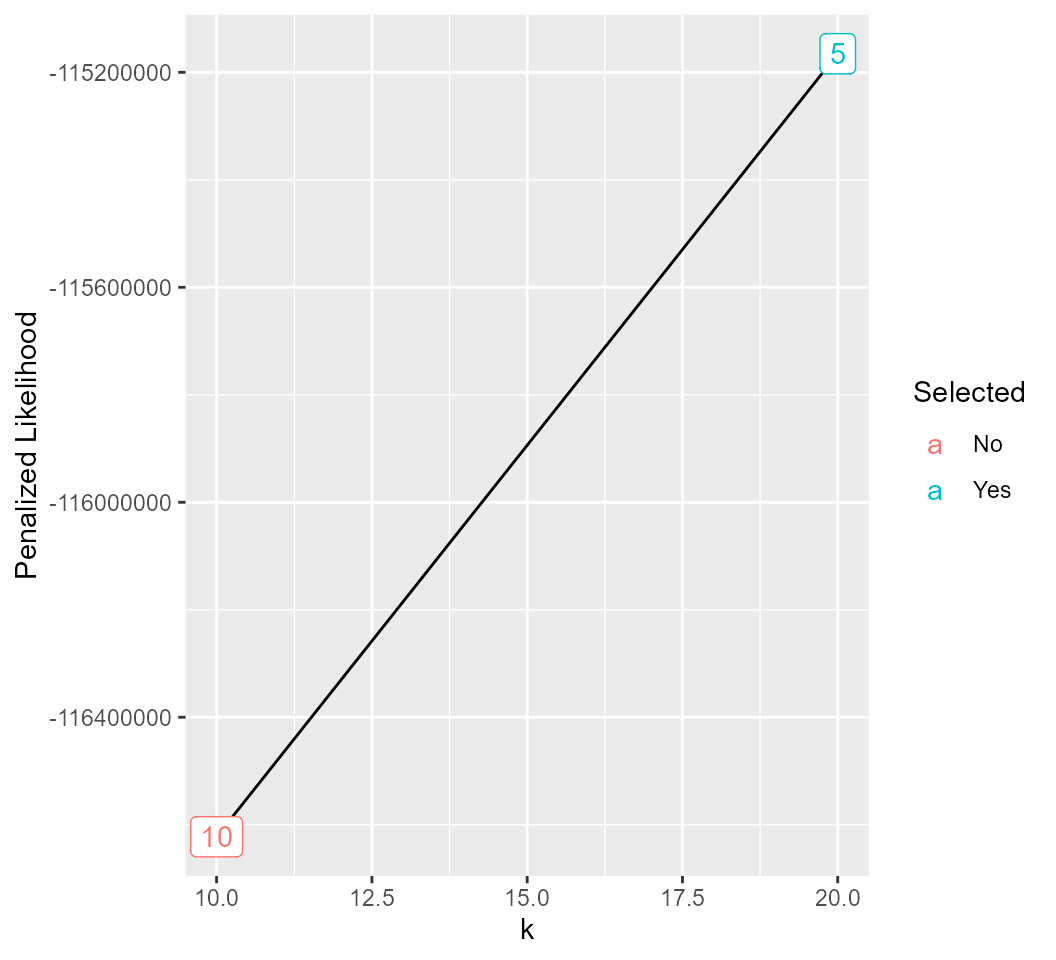
We can see that using the recommend procedure, the selected combination is (\(\lambda=15\), \(k=20\)). In practice, we recommend running for a much larger number of iterations (e.g. 1,000) and looking over a larger parameter space.